I find myself writing quick command line scripts every so often. They usually automate a random task from my daily routine and end up saving me a bunch of time. These scripts usually start as quick and dirty snippets, but once I figure that they are not a one-off thing, then I iterate to make them more usable.
There are several things that I find valuable in scripts like these:
- Their development cycle must be fast and iterative.
- They must support command line arguments.
- They must display progress bars during expensive operations.
- They must output the results in a human-digestable format.
I am pretty sure I am not alone on this, so I am going to share some of the tools that I use on my scripts to support the features above.
Caching HTTP responses during development
Building scripts that fetch data from the network can be a bit of a pain. Every time you want to test changes to your code, you have to re-fetch the data. In addition to slowing down the development cycle, you may very quickly hit API rate limits which will force you to stop until you’re clean again.
To avoid such issues, I’ve been using a library called
requests-cache that is a great companion
to requests. It basically creates a persistent cache so
that your script does not reach out to the server every time you run it. Using it is as simple
as importing it and installing a cache:
import requests
import requests_cache
requests_cache.install_cache('temp_cache')
response = requests.get("http://example.com")
When the script above is ran for the first time, requests-cache will create a temp_cache.sqlite
file and store the responses there. The next time the script is ran, no requests are going to hit
the server.
In some cases, it may be useful to specify an expiration period. For example, we can force
a cache invalidation after 1 hour by passing the expire_after parameter:
requests_cache.install_cache('temp_cache', expire_after=3600)
This library has boosted my development speed considerably. For more options, check out the requests-cache documentation.
Parsing Command Line Arguments
I was a long time argparse user, until I met click.
Click is so much simpler and yet very powerful. It allows me to define the arguments for my script
by simply decorating a function. Check out how simple it is to parse a couple command line options
with click:
import click
@click.command()
@click.option("--user", help="A GitHub username.")
@click.option("--days", help="The number of days to look back.", default=1)
def grab_stats(user, days):
click.echo(click.style(f"Hello, {user}!", fg="green"))
click.echo(click.style(f"Fetching the PRs/issues created in the past {days} days.", fg="red"))
if __name__ == "__main__":
grab_stats()
Check out the output of the script above:
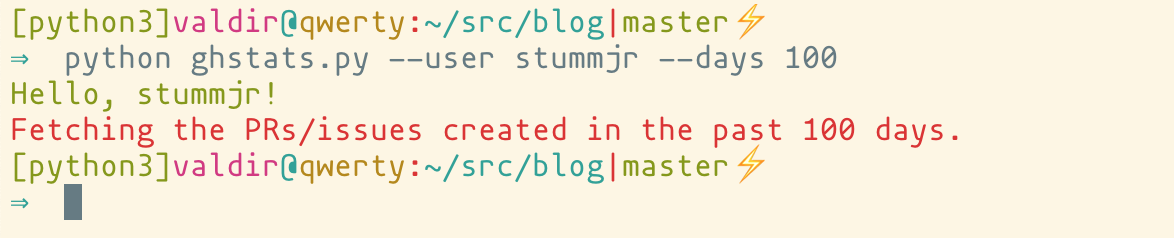
Click allowed me to easily format the output using click.style(), which is a great abstraction
around the terminal’s escape sequences.
Click’s echo() function is also quite helpful as it gracefully handles multiple types of
terminals, so that the script’s output looks the same no matter the terminal encoding.
Click also auto-generates help pages:
$ python ghstats.py --help
Usage: ghstats.py [OPTIONS]
Options:
--user TEXT The user's GitHub username.
--days INTEGER List the PRs/issues opened in the last 'days' days.
--help Show this message and exit.
This is the simplest example ever. Click is a very robust and feature-rich tool. For more info, check out the click docs.
Showing progress bars for the impatient
Every now and then I build a script that is just slow. Sometimes it’s because it’s reading a ton of files, sometimes it’s doing a bunch of HTTP requests and sometimes it’s just CPU heavy.
There’s nothing worse than staring at the screen as the cursor blinks without telling us anything. Progress bars are excellent at giving the users a sense of (uh …) progress. A simple progress bar like this helps users to estimate how much time they’ll have to wait:

Adding progress bars to Python scripts is super easy with tqdm.
Let’s say that we have a script that goes through a bunch of URLs making requests to fetch their
resources. This is all we have to do to show a nice progress bar to follow through the progress:
from tqdm import tqdm
...
for url in tqdm(urls):
resp = requests.get(url)
...
Pretty simple, huh? It’s so simple that it’s hard to notice where the progress bar is being introduced.
Again, this is just the simplest thing we can do with tqdm. It is super configurable and even provides
a command line tool so that you can add progress bars to your shell scripts. For more info, check out
the tqdm docs.
Tabulating the output
Isn’t it better when a script outputs a nice little table on the screen instead of a confusing
JSON object? The tabulate library is quite handy
as it allows us to easily plot nice ASCII tables with the output of our scripts:
from tabulate import tabulate
repo_pulls = [
("https://github.com/stummjr/flake8-scrapy/pull/13", "Drop usage of lambda as callback", "stummjr", "2018-10-20"),
("https://github.com/stummjr/flake8-scrapy/pull/12", "Forbid inline callbacks", "stummjr", "2018-09-20"),
("https://github.com/stummjr/flake8-scrapy/pull/11", "Document callbacks", "stummjr", "2018-08-20"),
]
headers = ("URL", "Title", "Author", "When")
table = tabulate(repo_pulls, headers=headers, tablefmt="fancy_grid")
print(table)
The script above will output a nice little table like this:
╒══════════════════════════════════════════════════╤══════════════════════════════════╤══════════╤════════════╕
│ URL │ Title │ Author │ When │
╞══════════════════════════════════════════════════╪══════════════════════════════════╪══════════╪════════════╡
│ https://github.com/stummjr/flake8-scrapy/pull/13 │ Drop usage of lambda as callback │ stummjr │ 2018-10-20 │
├──────────────────────────────────────────────────┼──────────────────────────────────┼──────────┼────────────┤
│ https://github.com/stummjr/flake8-scrapy/pull/12 │ Forbid inline callbacks │ stummjr │ 2018-09-20 │
├──────────────────────────────────────────────────┼──────────────────────────────────┼──────────┼────────────┤
│ https://github.com/stummjr/flake8-scrapy/pull/11 │ Document callbacks │ stummjr │ 2018-08-20 │
╘══════════════════════════════════════════════════╧══════════════════════════════════╧══════════╧════════════╛
This makes your quick and dirty scripts look more professional and it makes their output way more digestable. For more options, check out the tabulate documentation.
Wrapping up
I love writing scripts and I feel super proud when I am able to make one that’s useful and usable. I hope the tips I shared here can help you feel the same about your scripts.
And if you know any other helpful tools, please share them here in the comments as I’m always looking for ways to improve my own scripts.